This note documents a secondary prototype outside my main research agenda on multimodal retrieval and reasoning over video data. The goal was to test whether a low-cost arm and a desk robot could share visual inputs and execute a simple manipulation task.
The setup combined an SO-101 arm with Reachy Mini. The target task was to pick up a pen with the arm and present it to the robot.
The first difficulty was perception. The arm required a wrist camera for local visual feedback and the robot provided its own front camera, which created a two-view multimodal input stream.
The second difficulty was data collection. Standard leader-arm teleoperation was not usable in this setup, so I built a small phone interface to control the follower arm directly.

The phone interface exposed the wrist camera feed and two joysticks for joint control. This made it possible to collect task-specific demonstrations without a separate leader arm or a simulator.
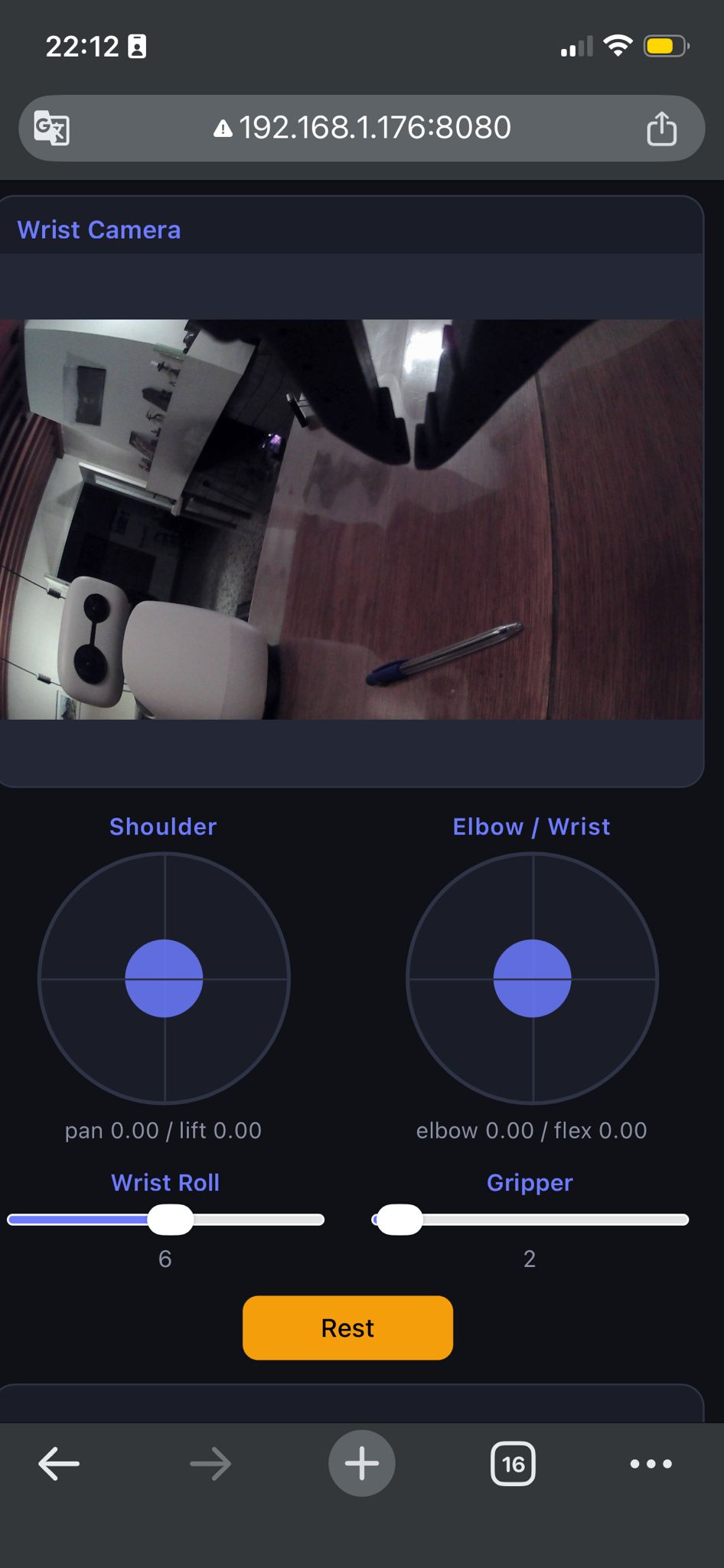
I recorded about 50 teleoperated episodes of the arm picking up a pen and presenting it to Reachy. This produced a small task-specific dataset with synchronized control and visual observations.
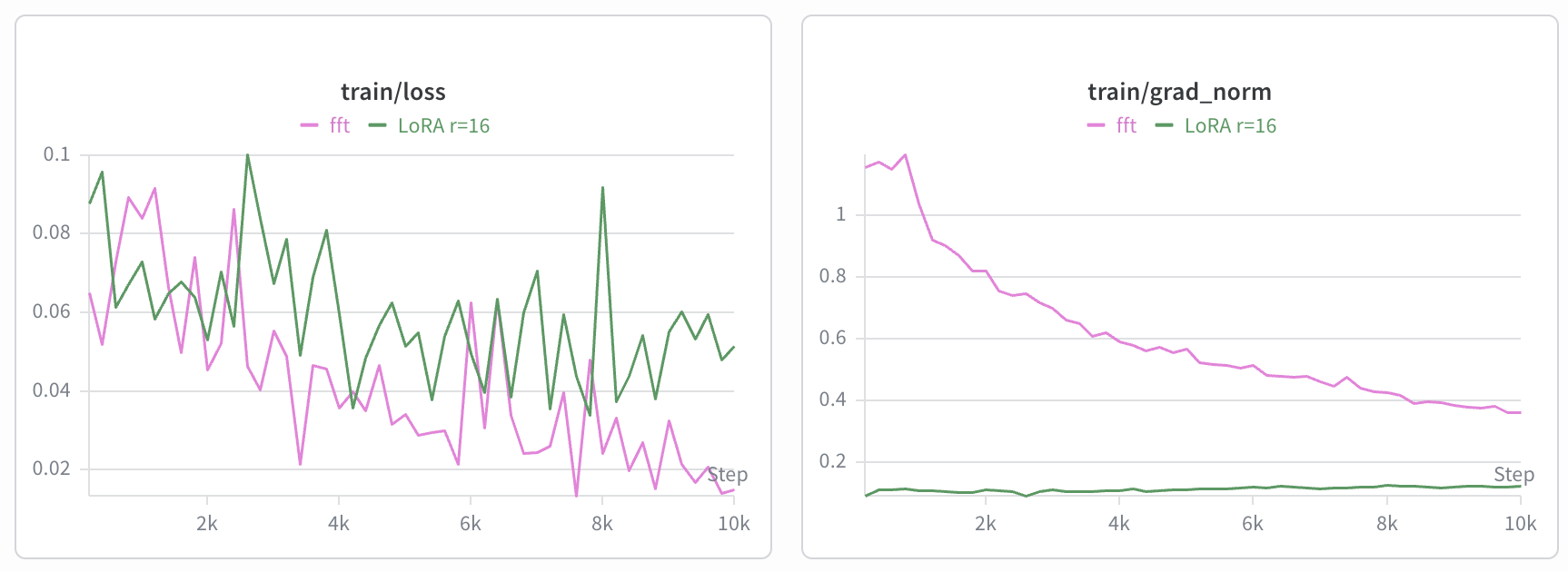
I used these episodes to fine-tune SmolVLA. In this setup, full fine-tuning produced better training behavior than LoRA and completed in about 9 hours on a MacBook Pro M3.
The resulting policy executed the narrow pick-and-present behavior on the desk setup. The scope remains limited, but the prototype was useful for studying multimodal perception, teleoperation, and small-scale data collection.