Research
I study multimodal retrieval and reasoning over large-scale video data. The work centers on indexing, evidence retrieval, and evaluation for long-form collections.
What I work on
The central problem is to retrieve the right evidence from long-form video and use it for reasoning. This is difficult because video is temporally distributed, weakly structured, and queried through language, metadata, and temporal constraints. I build systems that index video into searchable units and connect retrieval outputs to grounded reasoning pipelines.
A second problem is evaluation. Reported progress on video tasks can change with frame sampling, segmentation, and benchmark construction. I study evaluation protocols that expose those dependencies and support comparison under real operational constraints.
Research pillars
Video understanding
Long-form video carries meaning across time, modalities, and context. I build shot detection, chaptering, and multimodal representation pipelines that turn raw footage into structured, machine understandable units.
Video retrieval
Multimodal video queries require systems to align language, vision, and time. I design retrieval and reasoning pipelines that ground outputs in relevant video segments.
AI fairness
Models inherit and amplify the biases present in their training data. I study how disability, minority, and representation gaps propagate through vision and language systems, and how to evaluate and mitigate them.
Selected work
Curated for the core agenda of multimodal retrieval and reasoning over video data. The complete list is below.
-
Introduces a lightweight dynamic frame selector that distills caption-conditioned relevance from a teacher model for efficient low-budget video captioning.
-
Studies how to ground generation in large video libraries by retrieving relevant video segments as evidence. HSI 2024.
-
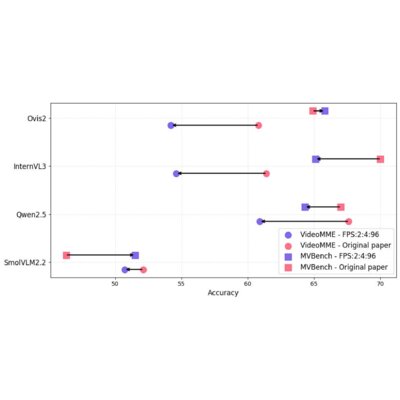
Shows that frame sampling changes measured video reasoning performance and provides a benchmark for more reliable comparison.
-
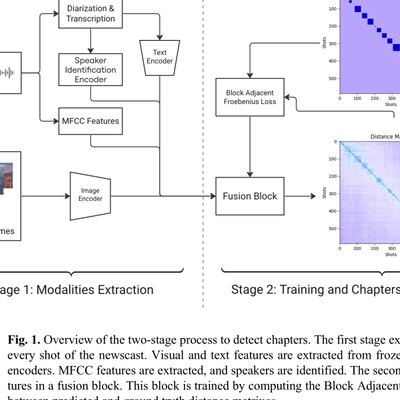
Addresses the lack of temporal structure in long broadcasts by building a multimodal chaptering pipeline for retrieval and analysis.
-

Builds a shot-level indexing method designed for large production video platforms. US 12,288,377 (2025).
Reviewing activities
I reviewed for ICASSP 2026, ICPRAI 2026, and ICME 2025. I also served on the scientific committee of JETSAN 2025.
Teaching
-
Speaker Diarization — Guest lecture
Publications
Recent work centers on multimodal retrieval and reasoning over video data. Earlier publications cover multimodal speech processing, robustness, and fairness, which inform the current research agenda. Authoritative citation data: Google Scholar.
2026
- Video understanding
PEEK: Picking Essential frames via Efficient Knowledge distillation
2025
- Video understanding
Frame Sampling Strategies Matter: A Benchmark for small vision language models
- Video retrieval
Computer-based platforms and methods for efficient AI-based digital video shot indexing
2024
-
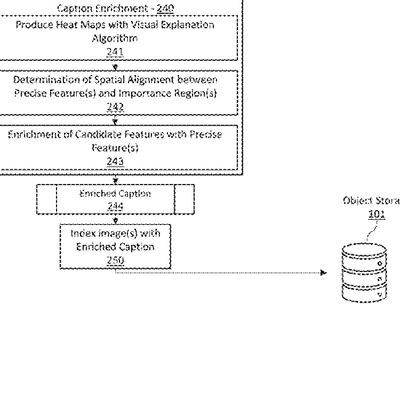 Video understanding
Video understandingSystems and methods for AI generation of image captions enriched with multiple AI modalities
- Video retrieval
Towards Retrieval Augmented Generation over Large Video Libraries
-

- Video understanding
Multimodal Chaptering for Long-Form TV Newscast Video
-
 Video understanding
Video understandingInserting Faces inside Captions: Image Captioning with Attention Guided Merging
- Speech processing
Privacy Preserving Personal Assistant with On-Device Diarization and Spoken Dialogue System for Home and Beyond
2023
- Speech processing
Diarisation multimodale: vers des modèles robustes et justes en contexte réel
- Speech processing
Détection d'activité vocale Multi-flux pour la Diarisation du locuteur
- Speech processing
Home monitoring for frailty detection through sound and speaker diarization analysis
-
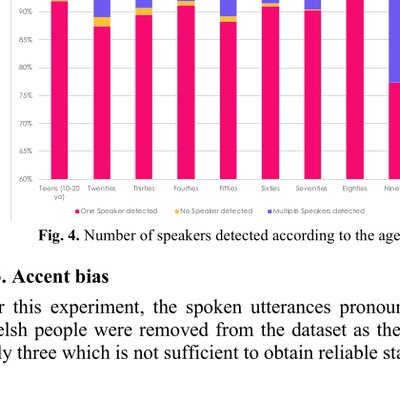 Fairness
FairnessTowards measuring and scoring speaker diarization fairness
2022
- Speech processing
Multi-stream voice activity detection for robust speaker diarization
- Speech processing
The Newsbridge-Telecom SudParis VoxCeleb Speaker Recognition Challenge 2022 System Description